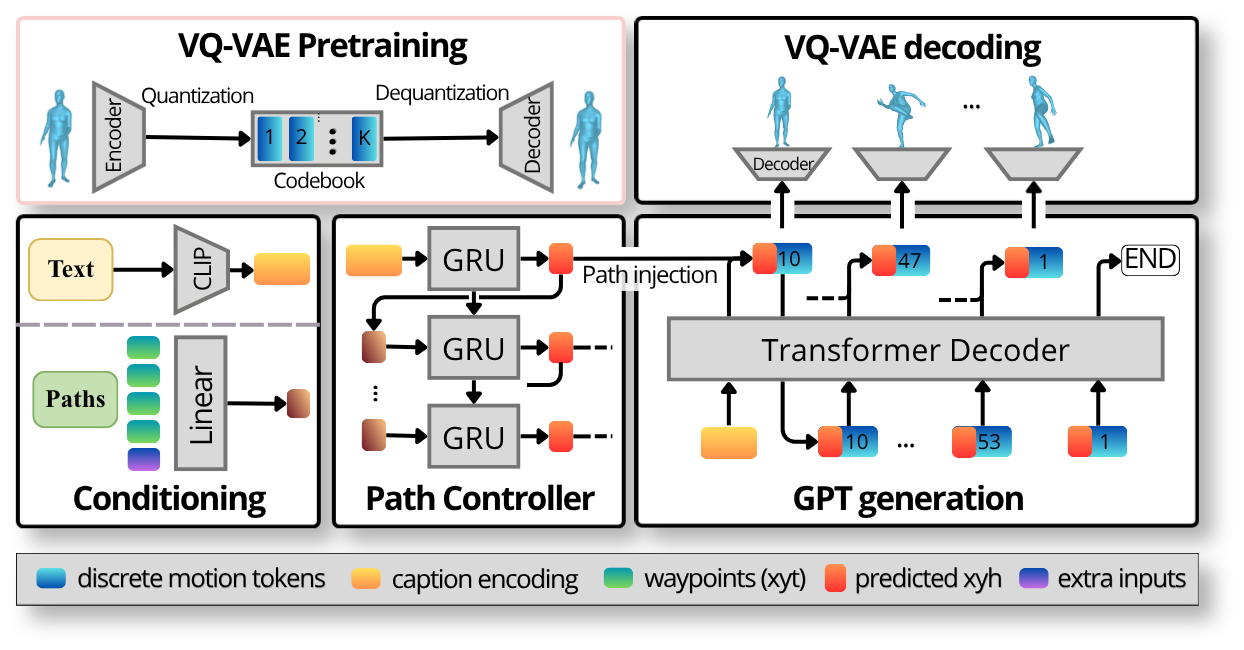
Text-to-motion systems like
Kimodo
generate high-fidelity human motion from captions and even support
spatial constraints, but they produce the entire clip in one shot. If
the user wants to change the path mid-motion, everything is recomputed
from scratch, which is too slow for interactive use and too rigid for
robotics, digital twins, or game characters.
We present C-T2M, a decoupled approach that splits
the problem in two: a small path controller that rolls
out the root XZ path (the line on the floor where the
character walks, given by a handful of waypoints), and a caption-driven
body GPT that synthesizes natural motion along that
path. A deterministic recompose step blends them. The controller can
react to new constraints instantly without re-running the body
generator, and the whole pipeline runs an order of magnitude faster
than Kimodo while following constraints with comparable accuracy. We
train and evaluate on
BONES-SEED,
a large motion-capture corpus covering everyday and athletic actions
(kicks, jumps, dances, locomotion), roughly 10× larger than the
standard
HumanML3D
benchmark, and the same corpus Kimodo trains on, so the comparison is
apples-to-apples. The full paper version of this writeup lives on the
Report page.
Key Capabilities of C-T2M
Four things our system does that motivate the design.
Text-to-Motion Generation
How does it work?
Text-to-motion is, at its core, the problem of placing every joint of a
humanoid skeleton frame-by-frame from a sentence. We start from the
T2M-GPT baseline, an
autoregressive Transformer that predicts discrete motion tokens from
text, and add one key piece: a separate
path controller that decides
where the character goes, leaving the body GPT free to focus
on what it does.
Step 1 of 6★ Our addition
VQ-VAE
A VQ-VAE...
Experiments
We evaluate on the BONES-SEED benchmark, comparing against
Kimodo under the same evaluation pipeline. Full setup, metrics,
and protocol details live in the Report.
1. Text to Motion
We first evaluate the unconstrained text-to-motion behaviour of our pipeline: given a
caption alone (no path constraint), can the model generate plausible motion that matches
the text? We report quantitative results on the Kimodo Repetition benchmark and show
qualitative samples from held-out captions.
Qualitative results.
Free-generation samples from our body GPT on captions held out from training.
Each clip is produced from the caption alone, with no path constraint, so what
you see is the model interpreting the text without any spatial guidance.
Ours vs. Kimodo (SOTA)
Side-by-side qualitative comparison on the same held-out captions. Kimodo is a
diffusion-based baseline (state-of-the-art quality, slow). What to look for: Kimodo (right)
produces smoother, more polished motion; our model (left) follows the caption
but shows slightly less smooth and refined joint trajectories.
This is the quality cost we trade for the speedup.
Caption: "The person, standing upright, draws their hand back to the right diagonal before throwing the ball diagonally to the left, then stands upright."
Ours (left) | Kimodo (right)
Caption: "A person standing straight stretches their leg and extends their arms outward, turns left and right, and stands in an upright stance."
Ours (left) | Kimodo (right)
Quantitative results.
On Kimodo's Repetition Text-to-Motion split (6 539 captions). The first two
charts show that we trail Kimodo on text alignment (R@3) and realism (FID).
The third chart, on a log scale, shows where we win: an order of magnitude
fewer parameters, fewer GFLOPs per clip (the compute cost of one inference),
and faster inference on the same A100.
The three column groups are the text-to-motion test splits of the
Kimodo benchmark.
Each clip carries one overview caption plus a timeline
of fine-grained atomic-action segments.
Overview: one high-level caption
drives the whole clip.
Timeline single: prompt is a single
atomic action from the timeline.
Timeline multi: prompt chains
several atomic actions; tests transitions.
Results. Text-to-motion quality and
efficiency on the Kimodo Repetition split: we trade some text-match quality for a
model roughly 20× smaller and 10× faster than Kimodo.
2. Constraint following
We then evaluate the model under explicit path constraints: given a caption and a
target floor path (a 2D XZ trajectory), how closely does the generated motion
follow the path while remaining faithful to the caption? We report qualitative
samples on hand-drawn paths and quantitative results on Kimodo's path-following
split.
Qualitative results.
Free-generation samples on caption “a person walks forward at a neutral pace”
conditioned on the hand-drawn paths shown on the ground. The character
follows the path while the body GPT freely synthesises the gait.
Quantitative results.
The trade we make: path accuracy for foot quality.
On Kimodo's path-following subset (256 root-XZ testcases), the left chart
shows that we match the ground-truth lower bound on 2D root error and beat
Kimodo. The right chart shows the other side of the deal: Kimodo still
leads on foot-skate and contact consistency. Closing that foot-quality gap
is the next step.
Results. We beat Kimodo on path
adherence (~24% lower 2D root error) but trade away foot-skate quality: the
expected cost of decoupling the controller from the body GPT.Show details
Our pipeline matches the ground-truth lower bound on root-2D adherence to within
two millimetres and undercuts Kimodo by roughly one centimetre (24 percent
relative error reduction), with a higher fraction of frames inside the
ten-centimetre tolerance (95.7 percent versus 93.4 percent). Kimodo wins
decisively on the foot-skate suite: a five-fold lower skate ratio and a
1.66 higher contact consistency. This is the expected trade-off of decoupling:
our explicit controller produces a clean world-frame path that the body GPT was
not jointly trained to follow, so when the controller-imposed path disagrees
with the body's predicted gait the feet slide. Kimodo's diffusion model jointly
generates body and root, avoiding the disagreement; the same property is
consistent with the VQ-VAE-ceiling foot-skate reported in the VQ-VAE reconstruction
ablation. A foot-projection post-processing step would close most of this gap
(Kimodo enables one by default) and is left to future work.
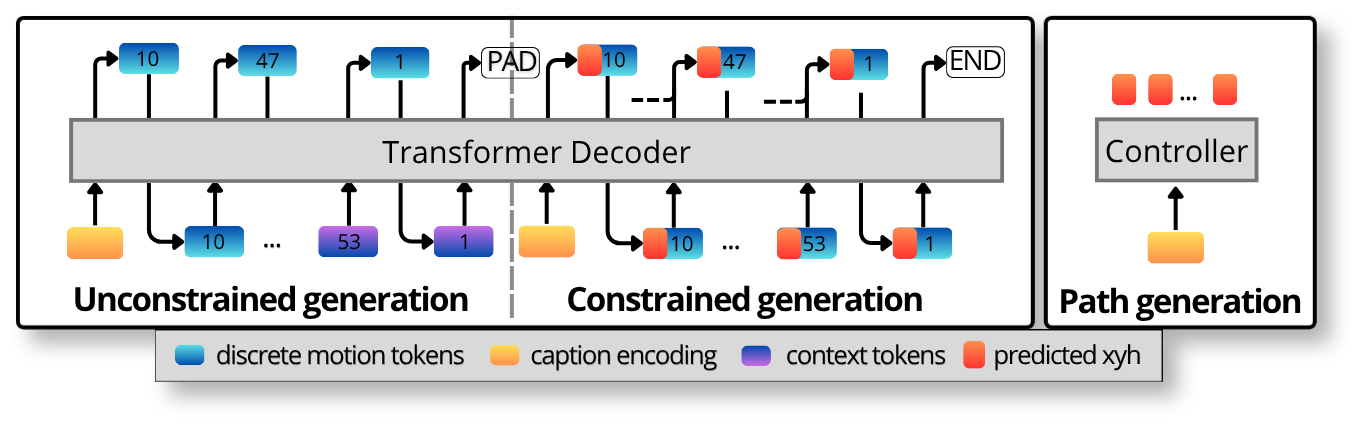
3. Online adaptation
Beyond static text-to-motion and constraint following, our pipeline can adapt motion
during generation. Because the model is autoregressive, a new text prompt or
a new path constraint can be injected mid-rollout and the body GPT continues from
there without restarting. The figure below sketches the mechanism; the rest of the
section shows it in action and reports the latency that makes it interactive.
Figure 8. Online adaptation via
interrupt-and-re-generate: cut the sequence, keep recent tokens as context, and
re-generate the rest under a new condition.Show details
At an arbitrary frame the sequence is cut and the last few
generated tokens are kept as context. A new condition (a different
text prompt, a new path constraint, or both) is then fed to the model, which
re-generates the remainder of the sequence from that point.
Because the context comes from the already-generated tokens, the transition is
smooth rather than an abrupt reset.
Qualitative results: Text prompt injection
We can change what the character does mid-sequence by injecting a new text prompt.
For example, starting from "a person walking forward at a steady pace" we
can inject "a person sits criss-cross" or "a person starts walking
right" and the motion adapts accordingly.
“a person walking forward” → “a person sits criss-cross”
“a person walking forward” → “a person starts walking right”
Qualitative results: Path constraint injection
We can also inject a new path constraint mid-sequence. This is useful when the
environment changes, for instance when a new obstacle appears and the character
must reroute. We show two cases: waypoints specified manually, and waypoints
computed automatically with the A* algorithm to avoid obstacles.
Manual waypoints
A* path around a new obstacle
Per-block inference cost of the decoupled pipeline
From caption to motion in 413 ms, or roughly
2.4 clips per second: fast enough to replan the path
on the fly during a rollout. The path controller and the body GPT account
for 96 % of the wall-clock cost; the CLIP encoder, the VQ decoder
and the recompose step are negligible. The second bar shows Kimodo on the
same A100 for reference, ≈ 10× slower end-to-end.
caption: "a person walks forward"Idle. Press play to run.
Body GPT autoregressive sampling (51 tokens, 30M parameters)
217.00 ± 1.70
52.49
VQ decoder
1.51 ± 0.08
0.37
Recompose, time-warp and reprojection (CPU)
7.76 ± 2.52
1.88
Total
413.40
100.00
Latency. End-to-end inference is
413 ms per clip (2.4 clips/s): the body GPT sampler and trajectory
controller together account for 96 % of the cost, while the VQ decoder and CPU
recompose are effectively free.Show details
Measured on a single A100 80GB, fp32, batch size 1, 200-frame clip, mean ±
standard deviation over 50 runs after 10 warmups. The two autoregressive components
dominate: body GPT sampling over 51 tokens (217.00 ms, 52.5 %) and the GRU
path controller (179.73 ms, 43.5 %). The CLIP caption encoder
(7.40 ms), VQ decoder (1.51 ms) and CPU recompose/reprojection
(7.76 ms) together add under 4 % of the total.
4. Sequential prompts (“and then”)
Sections 1 to 3 showed that the model can generate motion, follow paths, and adapt
online. One question is still open: how much of the text actually makes
it into the motion? Here we test captions that chain actions in time
(do X, and then Y); a
complementary ablation
tests simultaneous actions (do X while doing Y). We start from a basic
walking prompt and add one modifier at a time:
Level 1"a person walks forward"
Level 2"a person walks forward slowly"
Level 3"a person walks forward slowly and then stops"
Level 4"a person walks forward slowly, then stops and raises the right hand"
Level 5"a person walks forward slowly, then stops, raises the right hand, and waves"
Up to Level 3 the motion follows the caption: walking,
slowing down, stopping. From Level 4 onwards the character
no longer stops, the hand-raise and wave are partial, and the
"and then" structure is lost. Each action on its own is generated
correctly, so the gap is in chaining them: text is a lossy
representation of motion when one caption tries to encode an explicit
temporal sequence.
Level 1 "a person walks forward"
Level 2 "…walks forward slowly"
Level 3 "…and then stops"
Level 4 "…raises the right hand"
Level 5 "…and waves"
Blue = model captures the prompt correctly · Purple = model fails to follow the prompt
Want to go deeper? Explore the ablations
Five experiments that justify the design choices behind C-T2M. Click any card to jump straight to the section.
We presented C-T2M, a decoupled autoregressive text-to-motion pipeline that
follows user-specified root XZ paths. By delegating path control to a small
closed-loop GRU and letting a caption-driven body GPT focus on plausible gait,
our method matches Kimodo's constraint-following quality (3.94 cm vs. 4.88 cm
2D root error) at 10× lower latency and 20× fewer effective
parameters. Path and gait turn out to be separable problems: our
constraint-conditioning
ablation shows that four end-to-end variants that try to make the body
GPT follow waypoints by itself are dominated by the decoupled design on
every metric. The decoupled solution is cheap, modular, and well-suited to
online and interactive settings.
Limitations and future work
Because the VQ-VAE quantises one token per frame, it smooths out the
high-frequency detail that keeps the feet pinned to the ground, and that
shows up as foot-skating. It is the main remaining gap to Kimodo on the
foot-contact suite.
A Kimodo-style foot re-projection post-processing step would close most of
that gap and is left to future work. The recompose step also assumes a planar
floor and a single root XZ trajectory, so it does not yet generalise to
end-effector or full-body keyframe constraints. Finally, the path
controller currently accounts for almost half of the end-to-end latency; a
learned feed-forward controller could replace the closed-loop GRU and remove
the largest single latency block.
Individual Contributions
Maria Pilligua:
ran the initial experiments to replicate T2M-GPT and preprocessed the
BONES dataset (multiple times, with different pipelines). Prepared the
model and dataloaders to retrain on the Kimodo benchmark. Trained the
VQ-VAE at both small and large scale, trained our main model, and explored
several architectures for injecting constraints before arriving at and
training our current decoupled design. Rendered all visuals shown on the
page (except the online-adaptation demos) and designed every architecture
figure. Designed and ran all ablations and evaluations reported here.
Consistently pushed for results, kept the meetings on track, and helped
organise the team.
Pau Amargant:
Worked on defining the local, velocity-based motion representation.
Implemented first evaluation/benchmark pipelines based on the kimodo benchmark.
Helped debug and tune the VQ-VAE and evaluate different per feature loss weightings.
Implemented and trained the residual VQ-VAE and the GPT-RVQ-VAE.
Worked on visualization tools and huggingface-based online demo.
Miquel Lopez:
designed and implemented the data preprocessing pipeline, and set up the
initial training pipeline for the VQ-VAE and the body GPT. Attempted to
train a full constraint model supporting root-path, joint, and
end-keypoint-frame constraints (unsuccessful). Ran the heavy-compute
training jobs. Designed and implemented the online-adaptation architecture
and produced the online-adaptation demos.
Nahush Rajesh Kolhe:
Implemented the data preparation and training scripts for the
larger model. Designed and implemented online generation with
text input injected mid-generation, using a streaming generator
to render the motion live. Built the visualisation and the demo
for online generation.
BibTeX
@misc{ct2m2026,
title = {Controllable Autoregressive Text-to-Motion Generation},
author = {Amargant, Pau and Lopez, Miquel and Pilligua, Maria and Kolhe, Nahush Rajesh},
year = {2026},
note = {CS-503 Project, EPFL},
}